Native KV Cache Offloading to Any Filesystem with llm-d





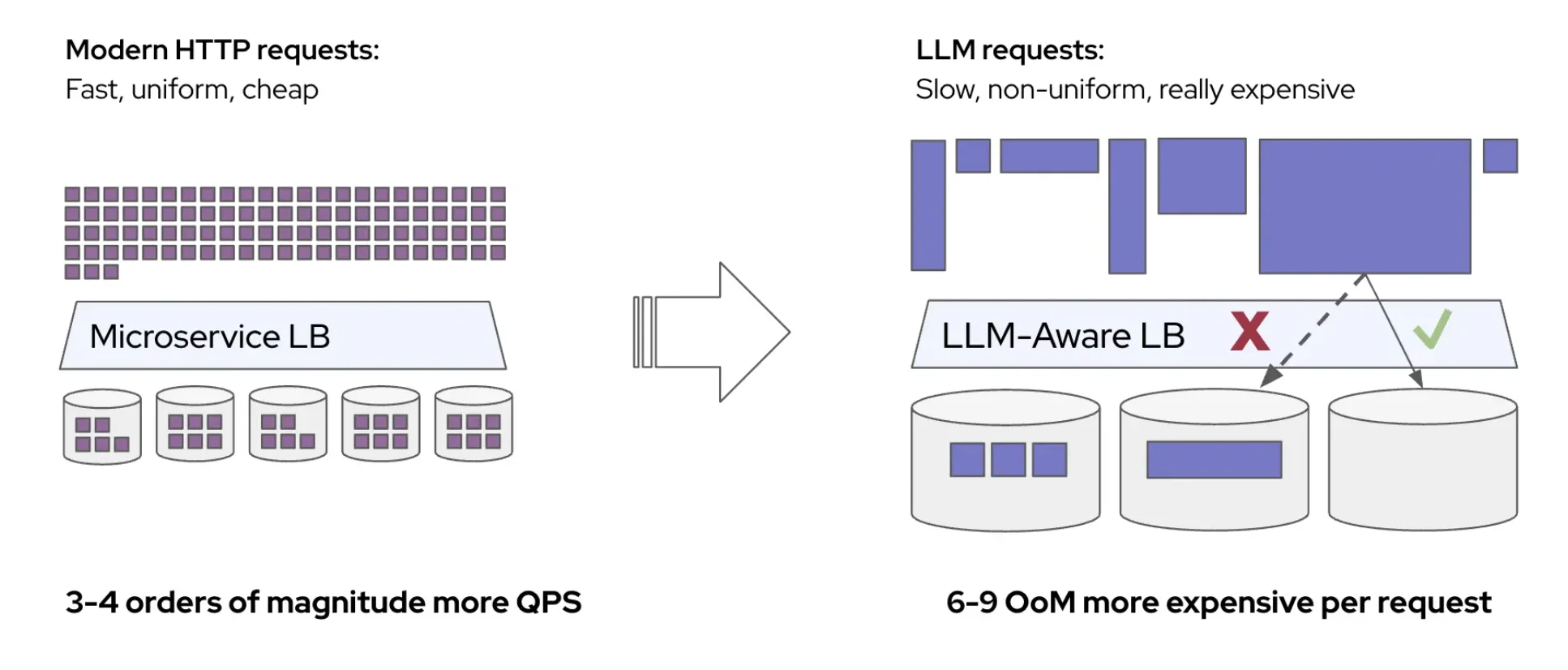
llm-d is a distributed inference platform spanning multiple vLLM instances. KV cache hits are critical to achieving high inference throughput. Yet, in a distributed environment, cache hits do not occur across different nodes as the KV cache is local to each vLLM instance. In addition, this local cache is limited in size, further limiting KV data reuse. This blog presents a new way to offload KV cache to storage, tackling both aforementioned challenges – KV cache sharing and KV cache scale. llm-d's filesystem (FS) backend is a KV cache storage connector for vLLM that offloads KV blocks to shared storage based on vLLM's native Offloading Connector. While the llm-d FS backend can speed up serving of single requests (improve TTFT), its main goal is rather to preserve stable throughput and low latency at scale, as concurrency and context lengths grow. This is accomplished by significantly enlarging the cache space and enabling KV reuse across multiple replicas and nodes in llm-d.
While there are a number of existing solutions for KV cache offload to storage (e.g. LMCache or Dynamo KVBM), the new connector offers simplicity, can run with llm-d and vLLM as the only dependency, and exhibits improved performance over state-of-the-art shared storage connectors.